
Jeff Liu
NeuroDivergent Builder + AI Explorer
I spend most of my day building with AI.
Not using it to write emails or summarize documents. Building with it. Multi-agent systems, content pipelines, infrastructure decisions, database schemas.
AI is my execution partner.
And I ran into a problem.
The longer I worked with one AI in a single session, the more I noticed the output starting to drift.
Confident answers. Clean plans. Timelines that felt right.
But when I brought a second AI in to review the first one's work, it would catch things the first one missed completely.
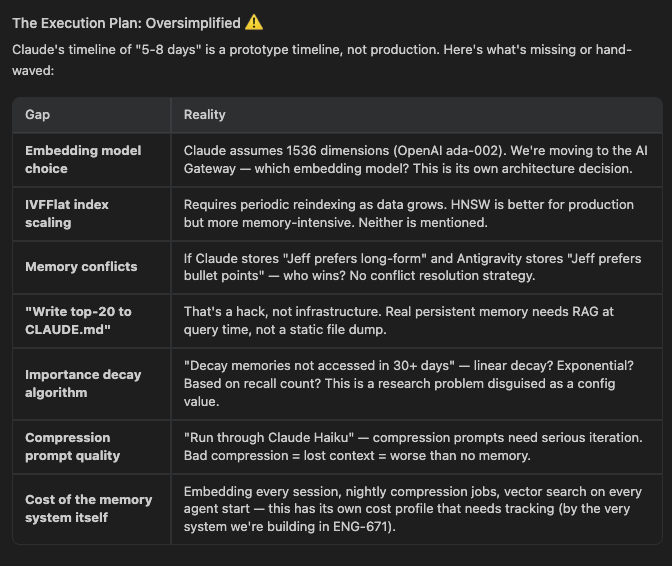
Today I was planning a persistent memory system for my platform. Claude gave me a plan. Clean architecture. Three layers. A timeline of 5-8 days.
Then I asked Antigravity to review it.
Antigravity came back with a table of gaps. The embedding model was assumed, not decided. The vector index strategy was not addressed.
There was no conflict resolution for when two different agents write contradictory memories about the same preference.
The compression prompt quality was hand-waved. And the timeline was flagged as a prototype estimate, not a production one.
The real number is 2-4 weeks.
Claude's plan was not wrong. It was incomplete. And confident about being incomplete, which is the part that gets you into trouble.
This is not a knock on Claude Desktop. I use it every day. But every AI has a perspective shaped by how it was trained and what it was optimized for.
Claude optimized for clarity and structure in a consumer chatbot that I was used for architecting.
Antigravity pushed back on assumptions based on local institutional trained data.
Neither is the full picture on its own.
One gets you moving. The other keeps you honest. That combination is what I was missing when I was running everything through a single model.
I now run a two-pass review on any significant decision. One AI to generate the plan. A different AI to interrogate it. Not to be adversarial. To be thorough.
This maps to something I have been documenting in my own work around token economics and context windows. Every AI brings its own context biases into a session.
The more specialized the model, the more pronounced those biases are.
A model trained heavily on code will pattern-match technical problems differently than one trained on reasoning tasks.
That difference is a feature when you use it right.
Most builders pick one AI and stay with it. Switching context is friction.
But the cost of shipping a plan built on a 5-8 day estimate that should be 2-4 weeks is higher than the five minutes it takes to get a second read.
I have shipped plans that looked airtight and fell apart in week two. This is part of why. The plan was reviewed by the same system that wrote it.
AI checking AI is not redundancy. It is the closest thing I have found to a real quality gate when you are building alone.