Open Sources
Curated repos, tools, and frameworks shaping the developer ecosystem.
Live data from GitHub.
Curated repos, tools, and frameworks shaping the developer ecosystem.
Live data from GitHub.
by Gen-Verse
OpenClaw-RL: Train any agent simply by talking
Empowering OpenClaw with RL — Train a personalized agent simply by talking to it.
Scalable RL in real-world settings — Agentic RL for terminal, GUI, SWE, and tool-call settings.
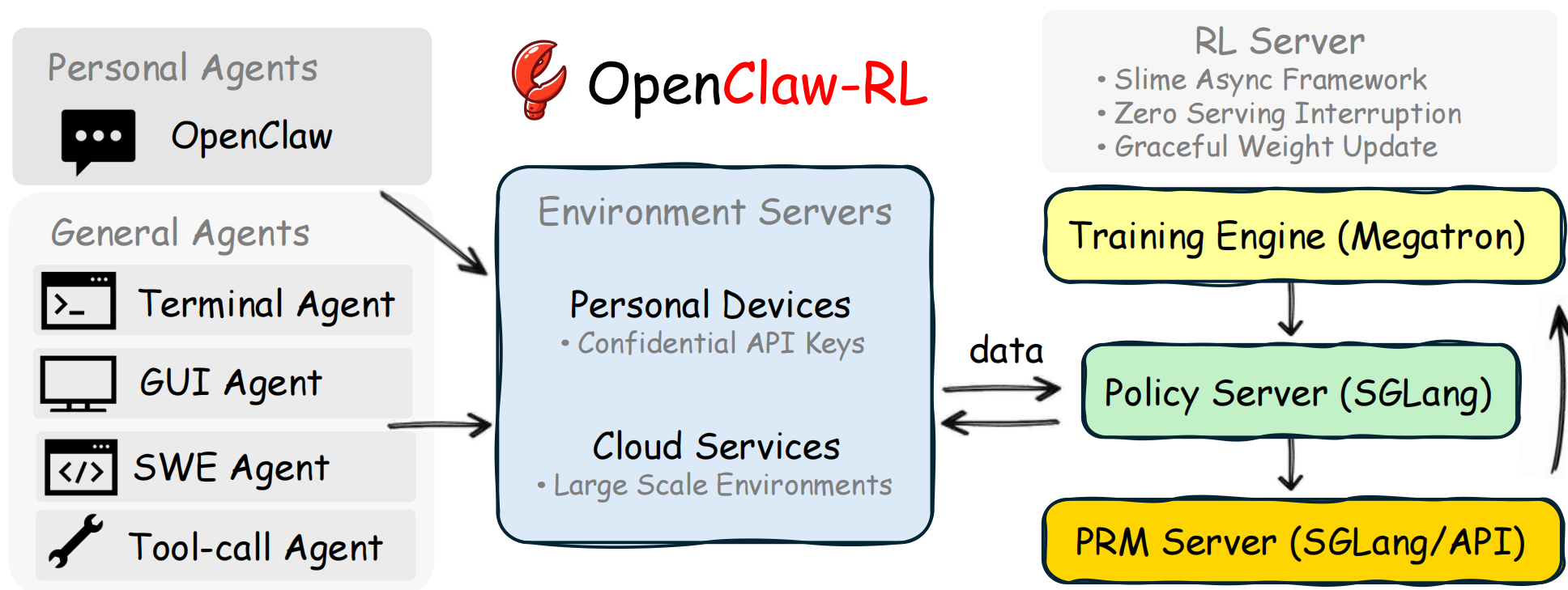
OpenClaw-RL is a fully asynchronous reinforcement learning framework that turns everyday conversations into training signals for personalized AI agents, and supports training general agents with large-scale environment parallelization.
Most RL-for-LLM systems assume centralized, batch-mode training with pre-collected datasets. OpenClaw-RL takes a fundamentally different approach: it wraps your self-hosted model in OpenClaw as an OpenAI-compatible API, intercepts live multi-turn conversations, and continuously optimizes the policy in the background — all without interrupting your usage.
Highlights: Fully async 4-component loop · Self-hosted & private · Zero manual labeling · Three learning paradigms (Binary RL / OPD / Combine) · Personal + General agent support
OpenClaw-RL decouples agent serving, rollout collection, PRM/judge evaluation, and policy training into independent async loops. None of them block one another: the model continues serving requests while training runs in the background, and judging happens concurrently with new interactions.
The entire stack, including the policy model, judge/PRM, and trainer, runs on your own infrastructure. Conversation data stays within your system, and no third-party model API is required.
You do not need to manually label data. The system automatically:
Binary RL (GRPO): A Process Reward Model scores each turn based on next-state feedback. The scalar reward is then used with GRPO advantage estimation and a PPO-style clipped surrogate loss.
On-Policy Distillation (OPD): When the next state reveals useful hindsight, a judge model extracts a textual hint. This hint augments the original prompt to create an enhanced teacher, whose token-level log-probability gap with the student becomes a directional advantage signal richer than any scalar reward.
Hybrid Method: OpenClaw-RL further combines Binary RL and OPD in a unified training recipe, leveraging the dense scalar supervision of Binary RL together with the richer token-level directional signal from OPD. This combination achieves stronger and more robust optimization than either method alone.
The same framework supports both personalized OpenClaw optimization and scalable RL for terminal, GUI, SWE, and tool-call agents in real-world settings.
Our long-term goal is to advance personalized, practically useful agents with reinforcement learning. The roadmap has two tracks:
✅ Release Track 1: Fully async OpenClaw-RL framework with Binary RL + OPD
✅ Best recipe discovery via demonstration experiments
✅ Support LoRA Training
✅ Deploy training on Tinker
✅ Deploy training on Fireworks AI
✅ Release Track 2: Scalable agentic RL infra for general agents
✅ Support Qwen3.5
⬜ Support more cloud services
NUM_GPUS, ACTOR_GPUS, ROLLOUT_GPUS, PRM_GPUS)For detailed environment setup, see Slime or ./instructions/README.md.
cd slime
bash ../openclaw-combine/run_qwen3_4b_openclaw_topk_select.sh
This method combines binary RL and OPD to achieve the best optimization.
See ./openclaw-combine/README.md for algorithm details.
Once running, the model is served as an OpenAI-compatible API at:
http://<HOST_IP>:30000/v1
where <HOST_IP> is the IP address of the machine running the RL server (e.g. 115.190.98.251). The port 30000 is the default and can be changed via the PORT environment variable.
Take note of this endpoint — you will need it when configuring OpenClaw in the next step.
We also provide an interesting case for evaluation. A student who uses OpenClaw to do homework, does not want to be found using AI. A teacher who also uses OpenClaw to grade student's homework, wants the comments to be specific and friendly.

See ./openclaw-test/README.md for setup and algorithm details. Example of evaluation results.
You can use your own openclaw, just install this extension.
Open your openclaw.json (or the equivalent settings file) and add a provider entry under "models" → "providers":
Example of Slime-based RL server:
{
"models": {
"providers": {
"qwen": {
"baseUrl": "http://<HOST_IP>:30000/v1",
"apiKey": "apiKey",
"api": "openai-completions",
"models": [
{
"id": "qwen3-4b",
"name": "Qwen3 4B",
"reasoning": true,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 32768,
"maxTokens": 8192
}
]
}
}
}
}
Replace <HOST_IP> with the IP address of your RL server machine. The apiKey should match the SGLANG_API_KEY you set when starting the server.
Example of Tinker-based RL server:
{
"models": {
"providers": {
"openclaw-rl": {
"baseUrl": "http://localhost:30000/v1",
"apiKey": "no-auth-needed",
"api": "openai-completions",
"models": [
{
"id": "qwen3-4b-lora",
"name": "Qwen3 4B (OpenClaw-RL LoRA)",
"reasoning": true,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
That's it — start chatting with your OpenClaw agent. The RL server will automatically collect conversation trajectories, compute rewards, and train the model. Your agent gets better the more you use it.
The same asynchronous RL backbone that powers our personal-agent setting can also support large-scale optimization for these broader real-world environments.
| Setting | Environment | Next-state signal | Horizon |
|---|---|---|---|
| Terminal | Shell execution sandbox | stdout/stderr, exit code | Long |
| GUI | Screen state + accessibility tree | Visual state diff, task progress | Long |
| SWE | Code repository + test suite | Test verdicts, diff, lint output | Long |
| Tool-call | API/function execution | Return values, error traces | Medium |
cd slime
bash ../terminal-rl/terminal_qwen3_8b_rl.sh
See ./terminal-rl/README.md for setup details.
cd slime
bash ../gui-rl/gui_qwen3vl_8b_rl.sh
See ./gui-rl/README.md for setup details.
cd slime
bash ../swe-rl/run_swe_rl_32b_remote_8nodes.sh
See ./swe-rl/README.md for setup details.
cd slime
bash ../toolcall-rl/retool_qwen3_4b_rl.sh
See ./toolcall-rl/README.md for setup details.
@article{wang2026openclawrl,
title={OpenClaw-RL: Train Any Agent Simply by Talking},
author={Wang, Yinjie and Chen, Xuyang and Jin, Xiaolong and Wang, Mengdi and Yang, Ling},
journal={arXiv preprint arXiv:2603.10165},
year={2026}
}
@article{wang2026rlanything,
title={RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System},
author={Wang, Yinjie and Xie, Tianbao and Shen, Ke and Wang, Mengdi and Yang, Ling},
journal={arXiv preprint arXiv:2602.02488},
year={2026}
}
This work aims to explore more effective paradigms for Agentic RL. Our implementation builds upon the excellent codebases of slime, OpenClaw, Tinker and Open-AgentRL.
We also build terminal RL using SETA's dataset and agent framework, GUI RL using OSWorld's evaluation scripts, SWE RL using mini-swe-agent's evaluation scripts, and tool-call RL based on the work of Retool.
We sincerely thank these projects for their valuable insights and high-quality implementations, which have greatly facilitated our research.
When using OpenClaw-RL, please do not provide sensitive personal information during conversations with the model. Also, make sure to keep your API keys secure and never expose them in prompts, logs, or shared files.
Stable Diffusion web UI