Open Sources
Curated repos, tools, and frameworks shaping the developer ecosystem.
Live data from GitHub.
Curated repos, tools, and frameworks shaping the developer ecosystem.
Live data from GitHub.
by NevaMind-AI
The memory harness for proactive AI agents — structured storage, intent capture, 10x token reduction.

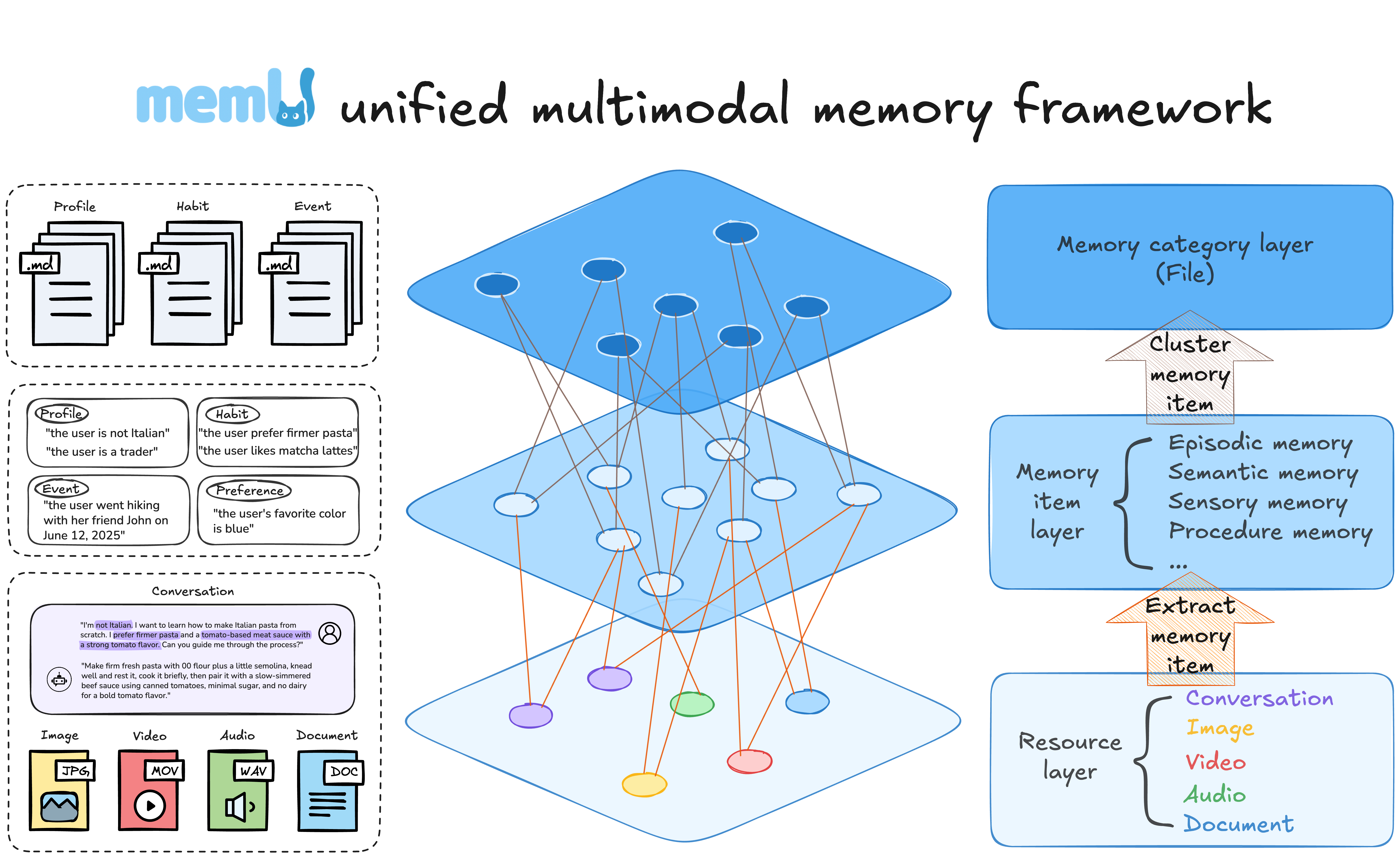
memU is a memory file system for AI agents.
Instead of flattening everything an agent learns into one giant prompt or an opaque vector blob, memU organizes memory the way you organize a computer — as a navigable tree of human-readable Markdown files:
MEMORY.md — the agent's living memory: who the user is, their preferences, goals, and the events extracted from every sourceSKILL.md — learned skills and tool patterns: what worked, what to avoid, and how to repeat recurring tasksINDEX.md — the table of contents: a navigable map across every memory file, so the agent knows where to look before it readsmemorize()s new sources into them and retrieve()s only the sections that matter on demandmemory/
├── INDEX.md ← map of everything: categories, files, and summaries
├── MEMORY.md ← profile, preferences, goals, and key events
└── skill/
├── {skill_name}/
│ └── SKILL.md ← a learned skill or tool pattern
└── {another_skill}/
└── SKILL.md
File system as memory: a hierarchical, browsable surface where every memory traces back to its source. Memory shapes the agent: because that surface is structured and self-organizing, it stops being passive storage and becomes the layer that shapes how the agent thinks and acts.
Think of it as two file-system operations: writing raw sources into organized memory, and reading the right files back into the agent.
WRITE — memorize() READ — retrieve()
────────────────────────────────────────────── ──────────────────────────────────────────────
raw files → extract → files + folders query → walk folders → ranked files
───────────── ───────── ────────────── ───── ──────────── ─────────────
chat logs → parse → profile / event items user / task query
documents / URLs → facts → knowledge / skill items │
images / video → caption → resources + summaries ├─ route + scope → relevant folders (categories)
audio → transcribe→ event / knowledge items ├─ rank by relevance → matching files (items)
tool logs → mine → tool / skill items └─ trace to source → original resources
Writing to the file system (memorize)
Resource (the raw file) with its modality and source locationMemoryItems (the files): profile, event, knowledge, behavior, skill, or tool memoriesMemoryCategory folders, cross-link, embed, and summarize into a browsable treeReading from the file system (retrieve)
memU's primary output is a navigable memory tree — folders, files, and the source artifacts behind them — persisted through repository contracts and returned as dictionaries from memorize() and retrieve().
MemoryCategory ← folder: a topic with an evolving summary
├── name, description, summary
├── embedding
└── MemoryItem[] ← files: typed, atomic memories
├── memory_type: profile | event | knowledge | behavior | skill | tool
├── summary, extra, happened_at, embedding
└── Resource ← source: the raw file this memory came from
└── url, modality, local_path, caption, embedding
| Record | File-System Role | Used By |
|---|---|---|
MemoryCategory | Folder — groups related memories and keeps a topic-level summary | Load compact context for broad queries |
MemoryItem | File — a typed atomic memory with a summary and optional metadata | Inject precise facts, preferences, events, skills, and tool patterns |
Resource | Source artifact — the original file behind a memory, with caption/text | Trace context back to where it came from |
CategoryItem | Link — the edge that files an item under a folder | Navigate related memories without reprocessing the source |
This gives agents a stable file system for memory: ingest raw sources once, then request scoped and ranked files instead of rereading every source artifact.
Every layer of the file system is stored as a structured record:
| Layer | What It Represents | Why Agents Use It |
|---|---|---|
| MemoryCategory | Auto-generated folder: a topic with an evolving summary | Load high-level context before drilling into details |
| MemoryItem | A file: atomic structured memory with a type and summary | Inject precise facts, preferences, events, skills, and tool patterns |
| Resource | Source artifact behind a file: conversation, document, image, video, audio, URL, or file | Trace memory back to its source |
| CategoryItem | The link that files an item under a folder | Navigate related memories without reprocessing the source |
| Embedding | Vector index over folders, files, and sources | Retrieve relevant context with low latency |
Example memorize() output:
{
"resource": {
"id": "res_01",
"url": "files/launch-meeting.mp4",
"modality": "video",
"caption": "A product planning discussion about onboarding and launch risks."
},
"items": [
{
"id": "mem_01",
"memory_type": "event",
"summary": "The team decided to simplify onboarding before the next launch review."
},
{
"id": "mem_02",
"memory_type": "profile",
"summary": "The user prefers concise implementation plans with explicit verification steps."
},
{
"id": "mem_03",
"memory_type": "tool",
"summary": "Use repository-wide search before editing configuration files to avoid missing duplicated settings."
}
],
"categories": [
{
"id": "cat_01",
"name": "product_goals",
"summary": "Current launch priorities, onboarding decisions, and unresolved risks."
}
],
"relations": [
{ "item_id": "mem_01", "category_id": "cat_01" }
]
}
Then an agent can call retrieve() to get a scoped, ranked context payload:
context = await service.retrieve(
queries=[{"role": "user", "content": {"text": "What context matters for this launch task?"}}],
where={"user_id": "123"},
)

If you find memU useful or interesting, a GitHub Star ⭐️ would be greatly appreciated.
| Capability | Description |
|---|---|
| 🗂️ Multimodal Ingestion | Write conversations, documents, images, video, audio, URLs, logs, and local files into memory |
| 📁 Memory File System | Persist folders (categories), files (items), source artifacts, links, summaries, and embeddings |
| 🧠 Typed Memory Extraction | Extract profile, event, knowledge, behavior, skill, and tool memories from raw sources |
| 🧭 Self-Organizing Folders | Auto-build categories, links, summaries, and embeddings without manual tagging |
| 🤖 Agent-Ready Retrieval | Read scoped, ranked context that can be injected into any agent workflow |
| 🧱 Pluggable Storage | Use in-memory, SQLite, or Postgres backends with the same repository contracts |
| 🔀 Profile-Based LLM Routing | Route chat, embedding, vision, and transcription work through configurable LLM profiles |
Turn chat logs into user preferences, goals, events, and relationship context.
await service.memorize(
resource_url="examples/resources/conversations/conv1.json",
modality="conversation",
user={"user_id": "123"},
)
context = await service.retrieve(
queries=[{"role": "user", "content": {"text": "What should I remember about this user?"}}],
where={"user_id": "123"},
)
Convert docs, PR notes, logs, and design decisions into reusable project memory.
await service.memorize(resource_url="docs/architecture.md", modality="document")
await service.memorize(resource_url="examples/resources/logs/log1.txt", modality="document")
context = await service.retrieve(
queries=[{"role": "user", "content": {"text": "How should I structure this module?"}}],
)
Extract searchable facts from documents, screenshots, images, videos, and audio notes.
await service.memorize(resource_url="examples/resources/docs/doc1.txt", modality="document")
await service.memorize(resource_url="examples/resources/images/image1.png", modality="image")
# Audio is supported for your own .mp3/.wav/.m4a files.
await service.memorize(resource_url="meeting-audio.mp3", modality="audio")
context = await service.retrieve(
queries=[{"role": "user", "content": {"text": "What matters for the next research plan?"}}],
)
Turn execution traces into tool memories that tell future agents when to use a tool and what mistakes to avoid.
await service.memorize(resource_url="examples/resources/logs/log1.txt", modality="document")
context = await service.retrieve(
queries=[{"role": "user", "content": {"text": "Which tools worked for config editing?"}}],
)
The memory file system is hierarchical enough for browsing and structured enough for direct retrieval:
| Layer | Primary Role | Retrieval Role |
|---|---|---|
| Category (folder) | Maintain topic-level summaries | Assemble compact context for broad queries |
| Item (file) | Store typed atomic memories | Load precise facts, events, preferences, skills, and tool patterns |
| Resource (source) | Preserve source artifacts and captions | Recall original context when item/category summaries are not enough |
See docs/architecture.md for the runtime view of MemoryService, workflow pipelines, storage backends, and LLM routing.
👉 memu.so — Hosted API for managed ingestion, structured memory, and retrieval
For enterprise deployment: info@nevamind.ai
| Base URL | https://api.memu.so |
|---|---|
| Auth | Authorization: Bearer <token> |
| Method | Endpoint | Description |
|---|---|---|
POST | /api/v3/memory/memorize | Ingest raw data and build structured memory |
GET | /api/v3/memory/memorize/status/{task_id} | Check processing status |
POST | /api/v3/memory/categories | List auto-generated categories |
POST | /api/v3/memory/retrieve | Query memory for agent context |
From a clone of this repository:
uv sync
# or, for the full development setup:
make install
To install the published package instead:
pip install memu-py
Requirements: Python 3.13+. The default examples use OpenAI, so set
OPENAI_API_KEYor pass another provider throughllm_profiles.
Run an in-memory smoke script:
export OPENAI_API_KEY=your_key
cd tests
uv run python test_inmemory.py
Run with PostgreSQL + pgvector:
uv sync --extra postgres
docker run -d --name memu-postgres \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=postgres \
-e POSTGRES_DB=memu \
-p 5432:5432 \
pgvector/pgvector:pg16
export OPENAI_API_KEY=your_key
export POSTGRES_DSN=postgresql+psycopg://postgres:postgres@127.0.0.1:5432/memu
cd tests
uv run python test_postgres.py
from memu import MemUService
service = MemUService(
llm_profiles={
"default": {
"base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"api_key": "your_key",
"chat_model": "qwen3-max",
"client_backend": "sdk"
},
"embedding": {
"base_url": "https://api.voyageai.com/v1",
"api_key": "your_key",
"embed_model": "voyage-3.5-lite"
}
},
)
from memu import MemoryService
service = MemoryService(
llm_profiles={
"default": {
"provider": "openrouter",
"client_backend": "httpx",
"base_url": "https://openrouter.ai",
"api_key": "your_key",
"chat_model": "anthropic/claude-3.5-sonnet",
"embed_model": "openai/text-embedding-3-small",
},
},
database_config={"metadata_store": {"provider": "inmemory"}},
)
memorize() — Structure Raw Data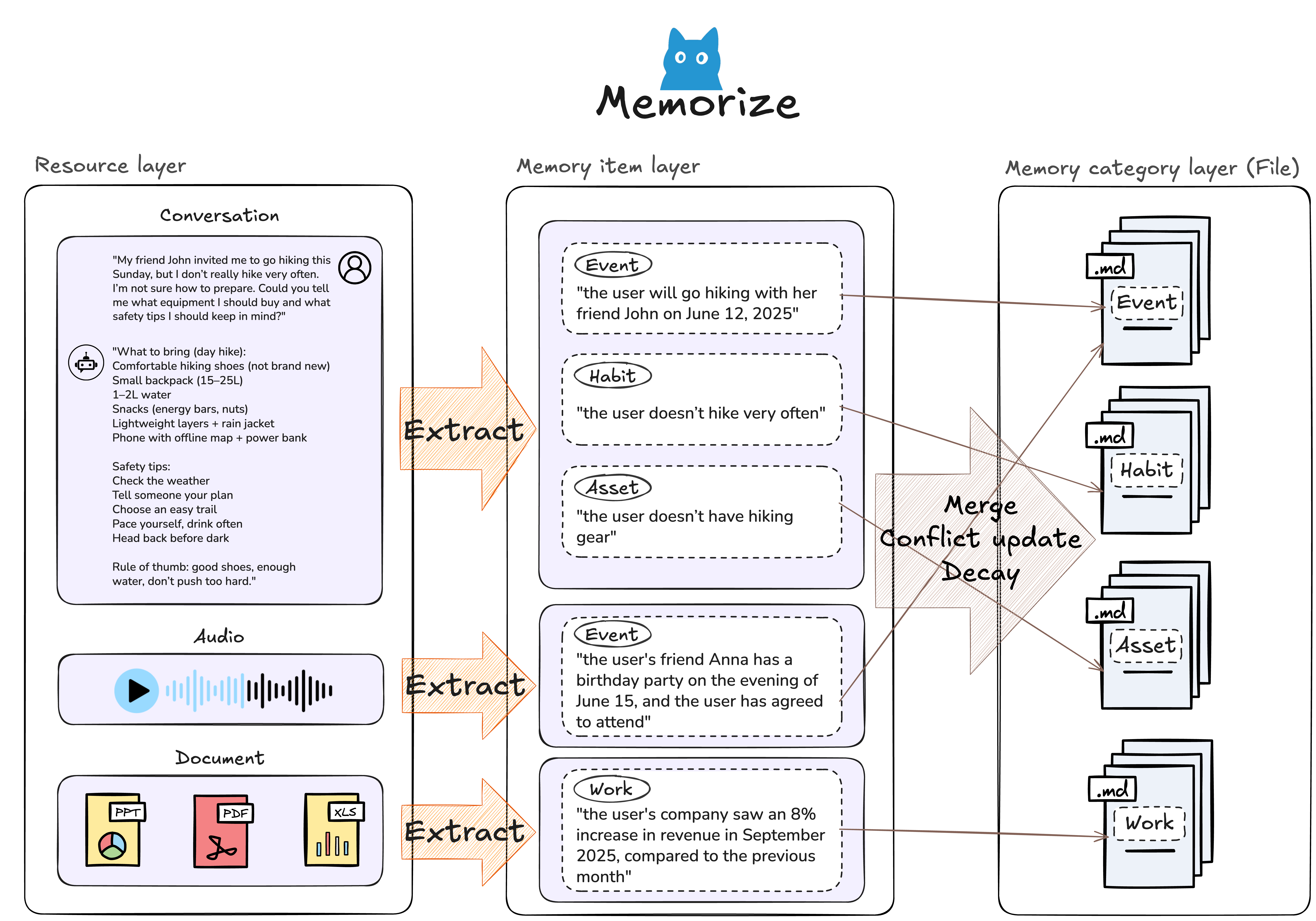
result = await service.memorize(
resource_url="path/to/file.json", # local file path or HTTP URL
modality="conversation", # conversation | document | image | video | audio
user={"user_id": "123"}, # optional: scope to a user or agent
)
# Returns after processing completes:
# { "resource": {...}, "items": [...], "categories": [...], "relations": [...] }
retrieve() — Load Agent Context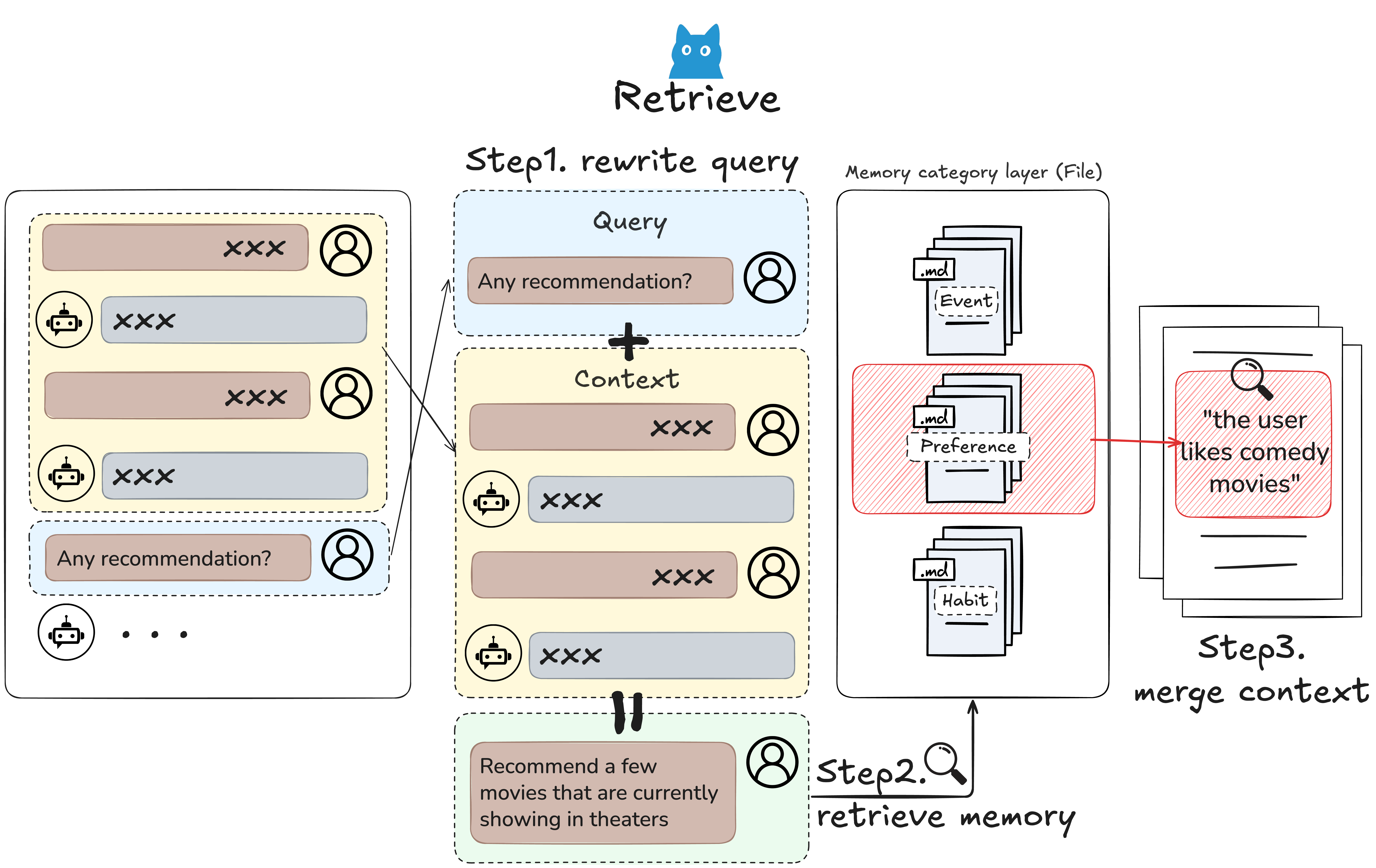
# The retrieval strategy is set once on the service via retrieve_config:
# MemoryService(retrieve_config={"method": "rag"}) # vector-first recall
# MemoryService(retrieve_config={"method": "llm"}) # LLM-ranked recall
result = await service.retrieve(
queries=[{"role": "user", "content": {"text": "What are their preferences?"}}],
where={"user_id": "123"}, # scope filter
)
# Returns:
# {
# "needs_retrieval": true,
# "original_query": "...",
# "rewritten_query": "...",
# "next_step_query": "...",
# "categories": [...],
# "items": [...],
# "resources": [...]
# }
retrieve_config.method | Behavior | Cost | Best For |
|---|---|---|---|
rag | Vector-first category/item/resource recall, with optional LLM routing and sufficiency checks enabled by default | Embeddings plus LLM calls unless route_intention and sufficiency_check are disabled | Fast scoped recall with controllable reasoning |
llm | LLM-ranked category/item/resource recall | LLM ranking at each tier | Deeper semantic ranking |
export OPENAI_API_KEY=your_key
uv run python examples/example_1_conversation_memory.py
Automatically extracts preferences, builds relationship models, and surfaces relevant context in future conversations.
uv run python examples/example_2_skill_extraction.py
Monitors agent actions, identifies patterns in successes and failures, auto-generates skill guides from experience.
uv run python examples/example_3_multimodal_memory.py
Cross-references text, images, and documents automatically into a unified memory layer.
memU achieves 92.09% average accuracy on the Locomo benchmark across all reasoning tasks.
View detailed results: memU-experiment
| Repository | Description |
|---|---|
| memU | Core memory file system — ingestion, extraction, retrieval |
| memU-server | Backend with real-time sync and webhook triggers |
| memU-ui | Visual dashboard for browsing and monitoring memory |
Quick Links:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
# Fork and clone
git clone https://github.com/YOUR_USERNAME/memU.git
cd memU
# Install dev dependencies
make install
# Run quality checks before submitting
make check
See CONTRIBUTING.md for full guidelines.
Prerequisites: Python 3.13+, uv, Git
⭐ Star us on GitHub to get notified about new releases!
Stable Diffusion web UI